0%
Robocup2D入门笔记(1)——概述
前言
我个人不是Robocup2D的专业选手,仅仅是在大一刚入学就接手了这项难度很高的项目,很多东西我也是在摸索当中逐渐总结出来的,希望能帮到同为入门的其他人,毕竟对初学者而言Robocup2D的资料确实挺难找,想要系统的了解需要耗费大量的时间和精力。文中难免出现错误,希望看到的各位大神能够帮忙在评论区指正,也是对新手的很好的教学。
目前打算做一套比较完整的入门笔记,从是什么开始,到基础知识的介绍,软件及环境的安装,球队的基本组成,以及常用的开发工具的介绍,希望给新手提供一个全套的教程顺利渡过前期最艰苦的时期。
1. 什么是Robocup2D
1.1 Robocup
Robocup是一项非营利性的科学挑战,目标是在2050年实现组建一支机器人足球队在世界杯赛场上战胜人类队伍,目前该项目已经进行了20余年。而在原来的足球的基础上,现在逐渐发展出其他许多不同的应用场景,例如家庭工作、救援等任务。详情见官网。
Robocup的官网

1.2 Robcup2D
Robocup2D是机器人足球的模拟比赛,足球赛的模拟分为2D与3D两种,其中2D历史更加悠久,是最早开始的比赛之一,而3D近年来也取得了长足的发展,相比2D也跟加贴近真实。
这里重点介绍2D比赛。2D比赛经过二十多年的发展,已经逐渐成为一项战术策略非常成熟的赛事了,许多人类足球的战术策略都被用到了这里面,例如阵型、盯防、跑位、角球战术等,而2D的限制使得在比赛中位置更加重要(因为球和球员都只能在2D的赛场上移动,因此占住了位置就是卡死了进攻以及防守的线路)。
而当前世界上Robocup2D的顶尖球队有这么几支:来自日本的Helios,来自中科大WrightEagle,以及来自安徽工业大学的YuShan,其中Helios的开源底层代码agent2d是现在非常多球队的底层代码,是一套功能十分完善、适合开发的代码。这里顺便提一下,因为Robocup是一项研究型项目,所以代码的复用是被赛事官方所鼓励的,但是也不能直接全盘照抄(这种事发生过),赛事组委会赛后会询问你球队做了哪些改进。
2 关于Robocup2D的一些资源
国内虽然有Robocup2D的强队,但适合的资源数量不多,在这里统一整理一下:
Robocup2D赛事官网.
Gitee的软件地址如果忍受不了Github的下载速度也可以尝试这个,里面还集成了一键安装的脚本,可以实现傻瓜式安装
博主九月大人的博客
最开始就是从这个博主的博客中对Robocup的代码有了一点认识才逐步入了门。
3 Robocup2D需要哪些知识
3.1 Linux操作系统
Robocup2D的服务器是运行在Linux操作系统下的,所以所有球队几乎都会在Linux环境下开发、编译、运行,所以需要掌握Linux操作系统的一些简单操作,例如编译、安装、运行等。
3.2 C++
在Robocup2D当中,目前最主流的编程语言还是使用C++,当然也有部分球队会选择使用Java或者python,但是目前最主流的球队还是使用C++进行开发,特别是适用范围最广的Helio底层球队Agent2d是用C++进行开发,所以掌握C++的知识是很重要的。如果同样是大一初学刚刚学完一门编程语言(特别是用C语言入门的学生),那么在学习的时候需要把重点要放在C++中STL库的学习以及面向对象编程的学习。
3.3 Git
Git对于程序员来说是一个很重要的工具,特别是在多人协同开发的时候更是需要有一个强大的工具来管理每个人写的代码,Git就是一个很好的工具。关于Git的使用网上已经有很多教程了,从cmd界面到GUI界面的都有很多资料,这里就不做赘述了。
3.3 检索资料的能力
Robocup2D的资料在网上其实是比较难找的,许多文章都是介绍到安装环境就截止了,少有的代码介绍和球队开发的介绍其实都不太足够而且比较零散,这个时候就需要有强大的信息检索能力,能够在众多杂乱的文章中提取出信息加以整合变成自己的知识。
关于检索资料,可以尝试使用不同的搜索引擎进行搜索,采用更高效的搜索技巧来搜索资料,详情可以看这篇文章。甚至在必要的时候可以科学上网在外网找资料,当然这也就需要下面这个能力。
3.4 英文能力
Robocup毕竟是国外的比赛,甚至连说明书也都是用英文写的,很多的资料也都会使用英文,所以强大的英文能力以及对英文的熟练程度会很大程度上影响进程,当然这次项目也培养了我不惧怕英文的能力😂
3.5 阅读代码能力
阅读代码对程序员来说是一个必不可少的过程,而在Robocup2D的开发过程中不可避免地就会要读代码,这对前期上手是非常重要的,但是常用的agent2d的代码就已经有10万行了,涉及到的文件更是非常繁多,所以沉住气读懂代码也是很重要的一环。以后会出一期博客介绍agent2d的结构以及代码构成,给有需要的人参考。
3.6 心理方面
Robocup2D确实是一个非常复杂的项目,面对大量的代码,大量的文件,彼此之间还相互连接牵扯,对初学而言确实打击很大,所以需要有对抗挫折的能力以及在繁杂的事物中抽丝剥茧梳理的能力,但是只要开始走起来了,其实很多东西都会迎刃而解变得越来越简单,希望大家都能享受这样一个学习进步的过程。
4 Robocup2D是怎么运作的
这里仅仅简要的介绍一下整个程序是怎么运行的,具体的运行流程会在后面详细介绍。
简单地说,就是先开启一个叫做server(服务器)的进程(可以看作一个程序),这个进程负责模拟场上的情况,也包括和比赛双方进行通信。而在此基础上,官方开发了一个monitor(监视器),用于把server模拟出的数据做一个可视化的处理展现在一个“球场”上。而我们要做的,就是开发一个程序,这个程序可以与server进行通信,接受server传来的信息,做出决策,然后给server重新发送命令让server去模拟。而更具体的,我方的11个球员实际上是独立的11个进程,被称为client(客户端),每一个client都具有完整的接收信息做出决策的能力,同时这些client之间不可以私自进行通信,其实就是模拟了11个独立的球员,人家不可能心有灵犀对吧😀。球员(或者说client)之间的通信同样得走server,然后再通过server发送给其他球员。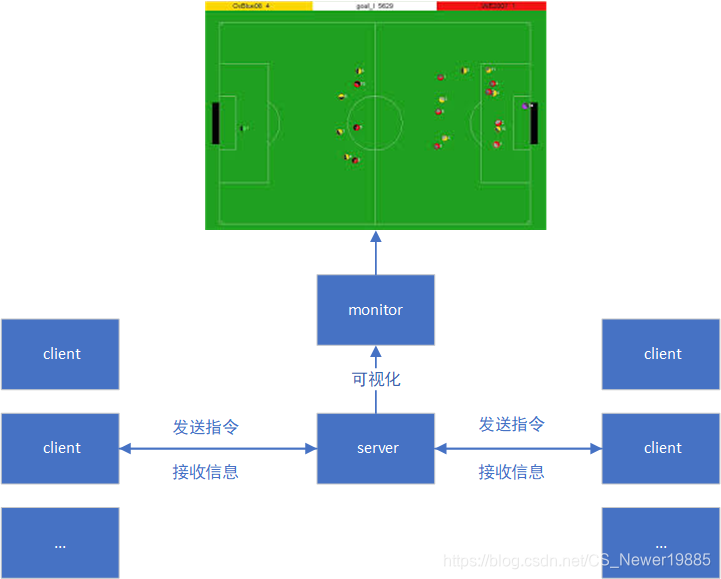
下一篇:Robocup2D入门笔记(2)——环境的配置与安装
Robocup2D入门笔记(2)——环境的配置与安装
本篇主要介绍Robocup2D环境的配置与安装,由于笔者去年安装的时候Ubuntu还是18.04的版本,server也还是15.6.0的版本,所以介绍的时候还是以这个软件版本为准,但会尽量兼顾新版本与旧版本的不同。
目录
环境的安装主要分为一下几个步骤:
- Linux环境准备
- 必要软件库的准备
- server及monitor的安装
- 球队的编译及上场
- 开始比赛吧
下面分别来介绍:
1.Linux环境准备
1.1为什么选择虚拟机+Ubuntu
整个Robocup2D需要运行在Linux环境下,所以需要配置Linux的环境。配置Linux环境主要有两种方式,一种是使用虚拟机,另一种是使用双系统,当然现在Windows10中也可以使用Linux子系统,去年我们曾经尝试过使用,但后来发现并不是很完善,所以没有采用。而相比双系统,虚拟机可以在Windows系统中作为一个软件来使用,我们认为这更符合我们平常的开发使用习惯,而Robocup2D项目对性能的要求也不高,所以最后我们选择使用虚拟机来安装Linux环境。
Linux本身是一个开源的操作系统内核,它能够完成诸如文件管理、硬件控制、进程协调等任务,但除此之外就没有了,而这样一个系统显然不适合拿来直接使用,所以在此基础上,产生了许多Linux发行版,就是在原来Linux的内核基础上加入了常用的程序库、编译器等东西,使它更适合大众使用。值得一提的是,虽然Linux本身是开源的,但在它基础上的一些发行版是收费的,当然也有许多好用的Linux免费发行版,例如Ubuntu,CentOS,Deepin等。
不同的Linux发行版各有特点,详细可见不同Linux发行版的特点。Ubuntu全球最热门的Linux发行版,安装简单而且有十分友好的图形操作界面,同时因为使用人数多出了问题也能比较容易查到解决的办法,所以我们选择使用Ubuntu作为Linux环境。
1.2 具体安装
先贴两个网址:
虚拟机资源
Ubuntu官方网址
分别在这两个地方下载虚拟机VMwar WorkStation以及Ubuntu。
之后的安装可以直接参考这篇文章:VMware安装Ubuntu18.04。
但是要注意这么几个地方:
在下面这个地方的时候可以直接选择中文,这样在后面可以不用再选择一次;
在硬盘分区这个步骤不要按照文中的做,直接默认即可,分了之后反而可能会在后面安装必要软件库的时候把区域的空间耗完。
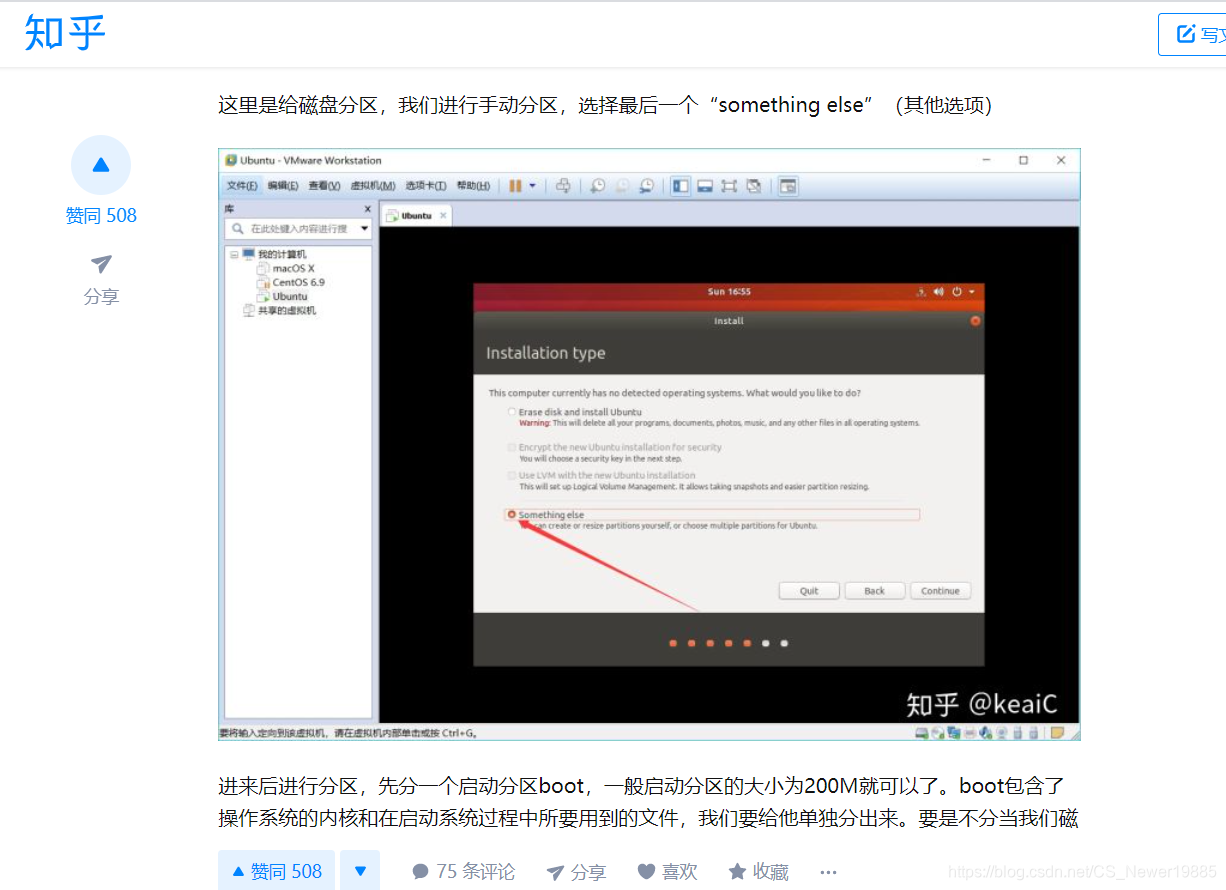
在terminal安装东西的时候可能会跳出如下的选项询问是否继续,这个时候需要手动在terminal中输入y/Y
关于管理员权限
在Linux中也有类似Windows中的管理员权限,在安装软件的时候会用上,sudo开头的命令就是以管理员权限运行的,也可以直接输入su进入管理员模式,以后所有命令就都是管理员权限的操作。
但是最开始我们明明没有设置管理员,但我们在安装软件的时候却要我们输入管理员密码,这可怎么办呢?
可以输入下面的命令设置管理员密码sudo passwd
注意终端里面输管理员密码是不会显示的。
完成之后Linux的安装这一步就算是完成了。1.3 Linux小试牛刀
在完成Linux安装后,可以先尝试下面这些操作来熟悉一下Linux
打开终端(Terminal)
打开终端有两种方式:- 直接在桌面打开

- 通过快捷键crtl+alt+t
打开后是这样的
- 直接在桌面打开
尝试一些基础命令
首先是查看当前所在目录
pwd
对应英语中的print working directory接着尝试打印当前目录下的文件
ls
对应英语中的list接着尝试移动目录
cd
对应英文为change directory
当然直接输入cd是不能改变目录的,必须要在后面接上一个参数告诉系统移动到哪个地方。./xxxx```其中xxxx可以在刚刚ls命令打印出来的文件夹中选一个 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70```cd ..```会返回上一级目录
**注意cd和后面的参数之间要有一个空格**
- 打开一个文件
```./xxxx```
注意这个文件必须在当前目录下,如果不确定可以先用ls命令查看;
同时文件的后缀名也要带上。
- 创建新目录
```mkdir xxxx```
对应英文make directory
可以创建一个名为xxxx的文件夹
- 创建一个文件
```touch xxxx```
touch命令后接的文件如果不存在则会创建,如果存在则可以修改时间等
- 删除文件
```rm xxxx```
其中xxxx为待删除的文件。当然提到删除就不得不提到著名的删库跑路公式```sudo rm -rf /*```


**不建议大家尝试,虽然只是虚拟机但是重装还是挺麻烦的**
- 清屏
```clear```
刚刚打了这么多命令整个terminal有很多东西,为了更加清晰地查看信息,使用clear命令可以把整个terminal清空。
- 复制与粘贴
在terminal中单纯的```crtl+c```只能用来停止进程,所以复制与粘贴得使用```crtl+shift+c```与```crtl+shif+v```。
3. **一些有意思的操作(如果不想再浪费时间熟悉Linux可以跳过)**
- 无限复读
```yes xxxxxxx```
输入下面这个命令之后可以不断地复读;
- 瞅啥呢
```xeyes```
会产生一个眼睛跟着鼠标移动;
- 黑客入侵
如果看过黑客帝国会对里面的黑底绿字的代码流动界面印象非常深刻,而我们现在就可以实现这个功能:
首先安装一个插件```sudo apt install cmatrix```
之后直接运行```cmatrix```即可
- 可爱的小猫
一个小插件可以产生一只不停的跟着鼠标跑的小猫;
```sudo apt install oneko```
``oneko``
- 小火车
产生一列呼啸而过的蒸汽火车
```sudo apt install sl```
```sl```
- 格言警句
在代码写累了的时候可以看看大佬们的名言
```sudo apt install fortune```
```fortune```
当然也少不了唐诗三百首了
```sudo apt install fortune-zh```
```fortune-zh```
- 花里胡哨地打印系统信息
两个插件可以花里胡哨地打印系统信息
```sudo apt install screenfetch```
```screenfetch```
或
```sudo apt install linuxlogo```
```linux_logo```
- 担心错过重要日子?
```cal```
快速查看日期放置错过重要日子。
- pv命令
pv命令可以让输出匀速实现
```sudo apt install pv```
以后只要在命令的最后加上
```| pv -qL 10```即可。
到这里相信大家对Linux里的terminal都不那么陌生了,那么我们可以接着继续了。
## 2.必要软件库的安装
server需要以下这些软件库g++
make
boost
bison
flex1
当然直接安装可能会发现定位不到这些软件包,所以可以尝试下面这个命令:
sudo apt-get update;
sudo apt-get -y install libboost-dev;
sudo apt-get -y install libboost-all-dev;
sudo apt-get -y install g++ automake;
sudo apt-get -y install libqt4-dev libxpm-dev libaudio-dev libxt-dev; libpng-dev libglib2.0-dev libfreetype6-dev libxrender-dev libxext-dev; libfontconfig-dev libxi-dev;
sudo apt-get -y install libqt4-sql-sqlite;
sudo apt-get -y install rar unrar p7zip;
sudo apt-get -y install nautilus-open-terminal;
sudo apt-get -y install build-essential;
sudo apt-get -y install flex bison tcsh;
sudo apt-get -y install libpng16-dev;
sudo apt-get -y install libpng12-dev;
sudo apt-get -y install libglib2.0-dev;
sudo apt-get -y install zlib*;
sudo apt-get -y install libfreetype6-dev;
sudo apt-get -y install libfontconfig1-dev;
sudo apt install -y zsh git vim #qtcreator;
sudo apt install -y python-setuptools python-dev build-essential;
sudo pip install –upgrade pip;
sudo rm /var/cache/apt/archives/lock;
sudo rm /var/lib/dpkg/lock;
sudo dpkg –configure -a;
sudo apt-get autoclean;
sudo apt-get clean;
1 | 如果在安装依赖库的时候碰到```E: Could not get lock /var/lib/dpkg/lock-frontend - open 针对apt-get被占用的解决方案```这种问题,可以尝试依次输入下面的命令: |
sudo rm /var/lib/apt/lists/lock
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock*
sudo dpkg –configure -a
sudo apt update
1 | ## 3.server和monitor的安装 |
./configure
sudo make
sudo make install
```
完成之后在目录下会生成一个start.sh文件,在server已经开启的情况下,同样在这个目录下,输入:
```./start.sh```
即可把球队跑起来连接到server上。
- 已经经过封装的球队
一般已经封装过的球队是会有start.sh的文件,通常直接运行即可。当然有的可能没有.sh后缀,这个时候就不需要这个后缀。
但是如果只是一个球队,又不想再准备一个球队,怎样能先把比赛跑起来呢?这个时候可以把球队文件复制一份,接着在start.sh文件中修改teamname为另外一个球队名,就可以把这个球队再连接到服务器了。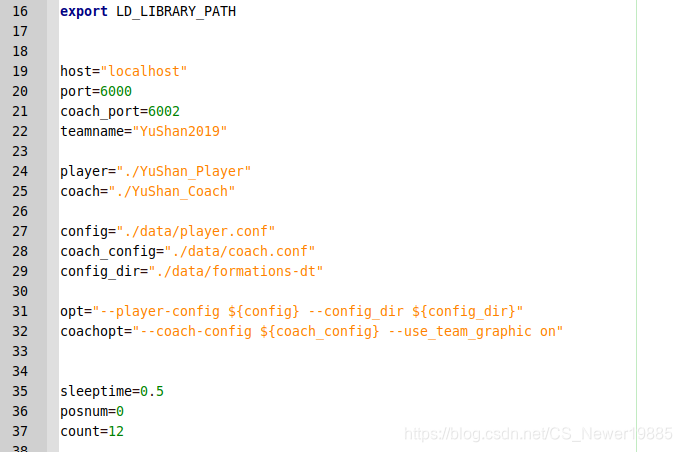
5.开始比赛吧
终于把两个球队都连接到server了,接下来到我们选中monitor界面,按下crtl+k,就可以开始比赛了。
如果想终止比赛,同样是选中monitor界面,按下crtl+q就可以终止比赛了。
最后,整个环境的配置与安装都已经完成了,当时我们在这个阶段也是经历了一段十分痛苦的过程,最后终于摸索出了这么一个办法,博客中的内容不一定正确,如果能帮到你那当然最好了,而如果发现有误,也欢迎在评论区或者私信进行讨论。
参考:
Robocup2D入门笔记(3)——比赛运行逻辑简介
在前面的几篇博客中我们成功在自己的电脑上把比赛跑起来了,但具体怎么跑起来的我们还是不太清楚,这一篇博客就简要介绍比赛是如何跑起来的。
一场Robocup2D的比赛主要分为server、monitor和client三个部分。
在server启动之后,会开放一个端口(一般是6000)用于本地的球队连接上去,如果是联机比赛那就是走一个ip地址+端口。之后我们利用脚本(start.sh)就可以快速启动我们的球队生成12个进程(1个教练+11个球员),这些进程就能通过预先设置好的端口连接到服务器上,连接成功之后就会执行后面的代码,将球员放置到场上准备比赛,当双方都连接好之后,在server下达一个开球的指令(crtl+k)就会开启比赛。
在比赛的过程中,我们看起来连续的图像实际上是离散的,1秒钟被分成了10个周期(也就是100ms一个周期),因为周期时间很短所以看起来就是一个连续的过程。在每个周期中,服务器都会发送信息到各个进程中,例如当前球员所能看到的听到的东西等;而每个进程也需要发送指令到服务器端,例如转动脖子,向前冲,踢球等,发送到server的指令会被server先检查一次,而且一个周期仅能发送一定数量的指令,防止恶意堵塞信道。如此循环下去直到6000个周期跑完比赛结束。
而monitor则是在每个周期中把server模拟出来的场上的信息进行可视化,例如某个球员在哪,球在哪,离散的点因为周期很短所以看起来也会是连续的。
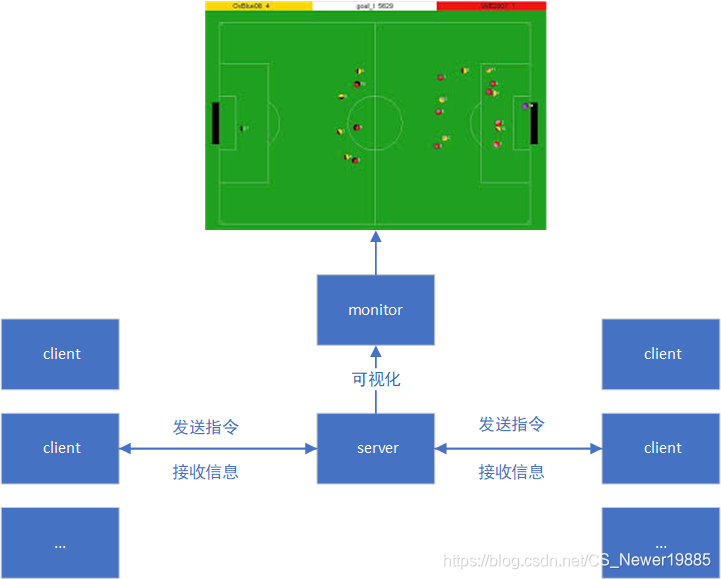
而在client中区分出了coach和player,coach这个client并不会显示在场上,也不会参与移动、踢球等指令,但是它可以发送信息给球员,而这个信息是不会受到球场噪音的干扰的(关于球场噪音可以看下一篇),但是会受到发送频率的限制。同时client也可以获得完整的球场信息,相当于一个拥有上帝视角的client,他可以审时度势做出球队整体的策略。
Robocup2D入门笔记(4)——常见模型
Robocup2D中有几个常见的模型,例如听觉、视觉、移动、踢球等,这篇博客主要介绍这几个常见的模型,这些模型也都可以在官方发布的说明书中找到(懒得找可以点这里)。
一、球场模型
Robocup2D的球场中存在一个坐标系,如下图所示,进攻方向是X轴的正方向,顺时针旋转90°后就是Y轴正方向,球场内的X的取值范围是[-52.5, 52.5],Y的取值范围是[-34, 34]。
注意左右两边的坐标轴方向是正好相反的,但是只要记住上面的坐标推导原则即可。
二、听觉模型
1、信息模板
球员端client接受到的听觉信息会是下面这样的:(hear Time sender "Message")
其中hear是保留字,用于区分不同的信息种类;
Time就是收到信息的时间;
sender指示信息从什么哪里传过来,如果是其他球员,就指示一个方向,如果是教练,就是online_coach_left或online_coach_right,如果是裁判就是referee,如果是自己就是self。
2、信道限制
除此之外,球员在一个回合之内最多只能听到一个由球员发来的信息,也就是说,如果两个球员同时向一个球员发出信息,这个球员只能接收到其中的一个。但是由教练,自己和裁判发来的信息可以允许与球员发来的信息并存。
3、交流范围
球员只能听到一定范围之内的信息,例如在己方球门的守门员说出的信息在前场的前锋就不能够听到了,这个距离是50个单位长度,也就是一个球员可以听到在这个范围内的一个球员发来的信息,而在这个范围以外的球员发出信息他就听不到了。
三、视觉模型
1、信息模板
(see ObjName Distance Direction DistChng DirChng BodyDir HeadDir)
see是保留字表示是视觉信息;
ObjName表示看到的物体是什么,注意在Robocup2D中,球员得自己通过观察到的球场上的标志物来推断自己的位置,服务器并不会将球员的坐标直接发送给球员;
Distance就是距离;
Direction就是方向;
DirChng,如果将两个物体连线看成一个向量,DirChng指的就是这个向量的模;
BodyDir和HeadDir就分别指的是当前球员身体和头的方向。
2、视觉范围
视觉的范围判定会比听觉要更加复杂一点。
球员所能看到的反围是当前头所在方向的一个扇形,这个角度被称为view_angle,这个角度可以有多种不同的取值,当然大角度对应的需要更长的周期才能获取到信息。
接着球员所能看到的东西也会随着距离的不同而不同,主要有unum_far_length,unum_too_far_length, team_far_length, team_too_far_length,这里分别介绍。
当dist<unum_far_length时,球员可以看到所在区域的球员的所属球队和号码;
当unum_far_length<dist<unum_too_far_length时,球员有一定的概率能够看到号码,但是依然可以识别出所属球队;
当unum_too_far_length<dist<team_far_length时,球员无法看到号码,但可以识别出球队;
当team_far_length<dist<team_too_far_length时,球员有一定概率可以分辨出所处球队;
当dist>team_too_far_length时,球员就无法识别出所属球队了。
3、噪音
球员的视觉信息会收到噪音的影响,而这个噪音的影响着球员对距离的判断,而且距离越远噪音越大。
四、动作模型
动作模型有很多,大家具体可以去看说明书,这里只挑几个重要的说明
1、移动模型
1.1 球员移动
球员的移动取决于球员发出的指令,如果球员发送dash指令,那么球员就会向前加速或者减速(向后dash),而如果没有发送dash指令就会按照一定的比例衰减速度。
1.2 球的移动
球的移动与球员的移动类似,也是如果没有人踢球,就会保持当前的方向移动,速度不断衰减,而如果有人踢就会获得一个新的速度与角度。
1.3 噪音
移动模型中同样有噪音的影响,为了模拟现实世界中那些没有被预料到的移动。
2、碰撞模型
碰撞模型主要针对两个物体重叠的情况,当发生这种情况的时候,系统判定为发生碰撞,两个物体都会沿着来时的路径被移动开直到两者不再重叠,同时速度都乘以-0.1
3、体力模型
球员是有体力限制的,而体力就被存储在一个叫体力池的地方,当球员发送dash指令的时候就会从体力池中减少体力。
但同时每个回合球员都会获得一些体力的恢复,甚至在有些时候球员的缓慢移动能够恢复体力(也就是才场上散步了)。而如果球员的体力消耗到一定程度了,它就无法再做快速的移动只能缓慢移动,直到体力逐渐恢复。
上一篇:Robocup2D入门笔记(3)——比赛运行逻辑简介
下一篇:Robocup2D入门笔记(5)——agent2d球队结构
Robocup2D入门笔记(5)——agent2d球队结构
本篇博客将重点介绍agent2d这个底层球队,agent2d本身也是当前最常用的一个底层球队,是helios团队开发出的底层球队,方便我们能够快速上手,将自己的想法付诸实践。点击进入下载地址,注意要先安装librcsc然后再安装agent2d的球队代码。
一、球队框架
agent2d的框架可以看下面这张图片: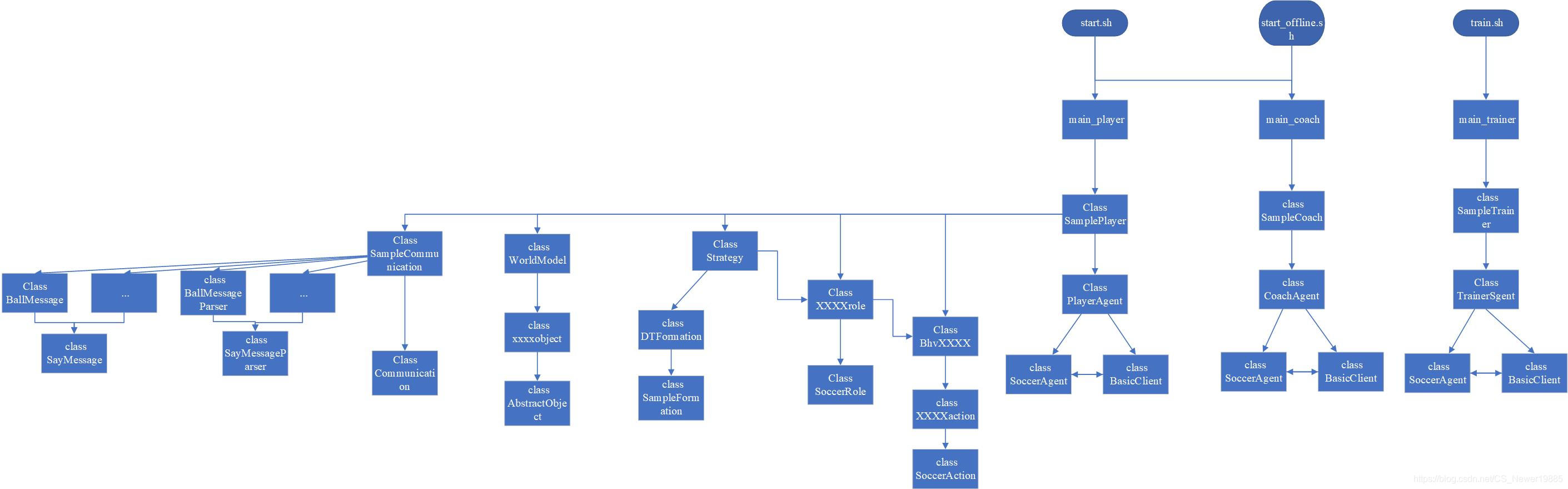
可以看到,agent2d总共有3个开始入口,分别是start.sh,start_offline.sh以及train.sh,分别对应普通模式开始,离线状态开始以及训练模式开始。
通过上面的脚本,开始运行main_player.cpp以及main_coach.cpp,这里面只用一个main函数,用于创建client并连线到服务器,从这里开始后面的一系列初始化的过程。
下一层级为samplePlayer以及sampleCoach,这个类可以认为是球员以及教练的大脑,球员类从这里衍生出了交流类(communication)、世界模型类(worldModel)、行为类(behavior)、策略类(strategy)、角色类(role)等,之后会详细介绍。
再往下是playerAgent类,这个类可以被认为是球员的身体类,它负责支配球员做出各种简单的动作,例如转身、踢球等。
最底层是soccerAgent以及basicClient类。soccerAgent类负责处理服务器发来的各种信息,例如比赛开始、比赛中止等;而basicClient类负责与服务器完成通信,从上层接收并发送指令到服务器,将服务器发来的信息上传到上层类。可以认为soccerAgent类就是介于底层通信类和上层抽象球员类之间的一个桥梁
二、交流类
这里的交流类指的是球员之间以及球员和教练之间的交流,可以主要分为三个部分,分别是信息类(xxxMessage)、信息处理类(xxxMessageParser)以及其他类;
在agent2d的球员交流之中,球员之间是用固定的信息模板来进行交流的,agent2d自带了一些固定的信息模板,例如要发送球的位置信息就得调用球的信息类来生成信息,生成一个带有固定前缀码(1个char)以及固定长度的信息,这里面就涉及信息的编码了;之后信息处理类先判断发送来的信息是否符合对应的要求(前缀码和长度),然后再对信息进行解码,获得信息并记录到memory类当中。
三、世界模型类
世界模型类(worldModel)是agent2d的一个非常重要的类,主要的功能就是记录球场的各种状态,例如球的位置,队友的位置,对手的位置,当然这里记录的信息是球员通过视觉或者听觉获得的,并不一定是正确的,会有一定的限制和偏差。
它下设了各种各样的object用于例如记录球以及队友对手的各种属性等等,而这些object类又是继承于AbstractObject类。
四、策略类
策略(strategy)在agnet2d中指的是球队层面的一些战术配合,例如阵型、角色分配等。
agent2d的阵型采用的是DT跑位,这里有必要多介绍一下跑位的相关知识。在Robocup2D的历史中,最开始是没有跑位的,这个时候球员基本都是追着球跑,没有什么战略性可言。之后随着项目的发展,出现了第一种跑位方式——SBSP,基于吸引子与排斥子的跑位,简单的说就是根据球的位置算出一个当前的跑位点,这样大家就不会一窝蜂的去追球了。之后继续发展,出现了DT跑位,通过delauny三角形先把球场划分开,然后以球在这些划分的三角形的交点处为情况设置阵型,而球不在交点的时候就采用三个交点的情形按比例计算出跑位点,具体可以看这篇文章。agent2d采用的是后一种办法。对应的类就是DTFFormation类,agent2d也封装了其他的跑位类,但是没有调用,而这些类都是基于SampleFormation继承而来的。
role类的话就是各种各样的球员角色了,例如守门员、前锋等,不同的角色会有不同的行为。
五、行为类
行为(behavior)在Robocup2D中可以认为是一系列动作(action)的组合,例如踢球是一个动作,但射门就是一个行为,因为射门需要首先确定踢球的角度力度等,踢这个动作只是简单的一环。
agent2d中封装好了许多动作和行为,行为类会调用对应的动作类。如果要修改推荐也是从行为上修改,修改动作相对来说效果并不会非常明显。
Robocup2D入门笔记(6)——总结及后续
一、 总结
Robocup 2D是一个基于C++的机器人足球模拟项目,球队通过开发程序实现一个能够与服务器进行交互的球队,因为开始时间较早,所以现在已经有了非常成熟的发展了,但发展成熟的代价就是新手入门会有很大的障碍,而通过本系列博客,我希望能够让新手在入门的时候能够有一个参考,虽然这些博客不能解决所有的问题,但希望能够让他作为一块敲门砖,让新手能够快速上手。
在接这个项目的时候我只是一名大一的新生,当时我还对这样一个项目没有什么概念,觉得这个东西应该会很好玩,而且也很有挑战性,甚至想着未来或许还能参加Robocup的比赛。但现实很快给我浇了盆冷水,当我忙活了接近2个月才把linux环境装好,运行环境装好,让球队顺利跑起来的时候,我就隐约意识到事情不对,再加上小组合作效果不好和疫情在家的影响,实际上项目做出来效果并不理想…不过现在总算是结束了,我也希望通过这些博客能够补充Robocup 2D在中文资料上的不足,给新手一个更友好的切入点,能够更好地把精力投入到球队的开发当中,也算是了却了我的梦想。
二、后续
那么对于看完我博客的人,如果你坚持希望继续在这个领域做的话,那么下面的几点建议或许可以用得上:
- 如果能够联系到有过相关经验的人,一定要好好把握,他们能够帮助解决很多问题,特别是前期的许多问题,他们往往也是踩着坑过来的,所以很多问题可能你抓破脑袋都想不出来他们可能能够很容易解决。
- 不要害怕英语阅读。Robocup2D在国内的资料目前还是不太充足,包括球队的TDP也要用英文来写,所以英文肯定是在这个项目中不可避免会碰到的,首先要克服对英文的恐惧,其实习惯了之后就会发现英文和中文一样只是信息传递的工具,并没有太多的不同,所以克服英语阅读的恐惧非常重要,不要总是想着使用翻译!!!
- 善用搜索引擎。搜索引擎的功能是很强大的,如果国内找不到合适的资料,Google或许是一个可行的选择,向stack overflow上就经常能找到许多问题的解决办法,而这需要英文阅读的能力,所以还是练好英语吧。
- 学会阅读文档等系统性文章。虽然博客可以解决局部的问题,但是很多时候要想真正对一个东西有一个系统全面的了解,还是要阅读系统文章以及原始资料,比如在这个项目中,Robcup2D官方的tutorial肯定是逃不开的,而读完这个之后你会发现会对整个项目有一个全新的认识,之后再去开发就会变得简单起来。
从零开始学习Git
@[TOC](0 目录)
1 简介
Git是什么
Git是一个免费开源的分布式版本管理系统。所谓版本管理系统,就是让我们能够在开发的时候更好地进行产品的迭代升级,以及回滚纠错,同时不需要冗长的命名,试想如果按照下图这样进行版本迭代该多头疼。也很容易发生错误。

Git的特点
- 分布式
Git的一大特点是其分布式的结构,所有版本信息仓库全部同步到本地的每个用户,这样就可以在本地查看所有版本历史,可以离线在本地提交,只需在连网时push到相应的服务器或其他用户那里。由于每个用户那里保存的都是所有的版本数据,只要有一个用户的设备没有问题就可以恢复所有的数据,但这也增加了本地存储空间的占用。 - 程序员导向
Git毕竟是一个面向程序员开发的软件,随处都可见程序员的思维习惯,黑色的命令行框框、晦涩难懂的正则表达式,导致普通人很难上手。虽然现在已经有不少带GUI界面的Git操作软件,但从原始Git中继承来的名词和繁杂的操作还是容易让人望而生畏。 - 较陡峭的学习曲线
上面提到Git程序员导向的整体气质,对许多刚接触Git的程序员来说,其学习曲线也是十分陡峭的,稍不留神就容易导致各种警告和冲突的出现,特别是如果在开发的过程中碰到问题则更让人抓狂,最后可能就会变成下面的漫画那样。
确实这种操作也是Git新手很容易出现的,毕竟我只是想拿来进行版本控制结果跳出了一大堆看不懂的错误,最简单粗暴的办法就是删了重装,但还是希望读者在看完这篇博客回去实践的时候,出现问题多想办法,总结错误,在这个过程中也能加深对Git的认识。当然最后如果实在时间紧急那还是删了重装吧😂。
- 分布式
Git的故事
关于Git的来源还有一个小故事。在Linus大神组织全世界的热心志愿者开发Linux系统的时候,同样面临着版本迭代控制的问题,而在Git发明之前,全世界的志愿者都是通过电子邮件将自己开发后的代码的diff,也就是修改的部分发给Linus,然后再由Linus手动进行代码合并,这样的效率显然是十分低下的,而在当时网络带宽的限制下,免费的分布式版本控制系统CVS、SVN之流速度非常缓慢,也遭到了Linus的弃用。手动合并的方式虽然繁琐,但是在Linux系统初期代码量还比较小的情况下还是能用的,但到了Linux系统十周年的时候,整个系统的代码量已经非常庞大了,再继续使用这种办法显然不是可行之举。恰逢此时有一家商用的版本控制系统公司BitMover愿意免费授权他们的产品Bitkeeper这些开发者使用,于是Linux社区开始使用这个产品进行版本控制。但是在Linux这个免费开源的系统的开发过程中竟然使用的是一个商用的版本控制系统,这在社区当时也引起了很大的争议,也有部分开发者对其进行逆向工程希望破解。最终这一行为被BitMover公司发现并取消了其授权,而Linus大神则在两个星期的时间里就重新用C语言开发出了Git这个传奇的版本控制系统,这就是Git的由来故事。点击查看更加详细的故事
2 Git基本概念
在对Git有了一个简单的认识之后让我们来先了解一些Git的基本概念,方便后续的讲述。
- 三个区域
在一个Git工作目录下,总共有3个区域,分别是工作区(working directory)、缓存区(stage)、版本库(repository),工作顾名思义就是当前你看到的文件夹中的文件以及正在修改的文件,而缓存区则是一个隐藏起来的区域,你可以通过Git命令将某个经过修改的文件从工作区转移到缓存区,而版本库则是记录之前版本的区域,你可以通过Git命令来将当前缓存区中的文件打包保存成一个新的版本,注意不在缓存区中的文件则是保持与上一个版本相同。 - 五种文件状态
在一个Git工作目录下,每个文件都会有四种状态,分别是未追踪(untracked)、未修改(unmodified)、修改(modified)、暂存(staged)、提交(committed),而后面四种可以被认为是已追踪的状态(tracked)。在Git的工作目录中,我们需要手动将新的文件“告诉”Git,也就是让Git能够去“追踪”这个文件,关注其是否被修改提交等。而列入追踪的文件如果没有发生修改则处于未修改状态,一旦这个文件发生了变化,则状态变为修改,此时这个文件可以被存入缓存区,进入暂存状态,而一旦我们将缓存区中的内容进行提交,则文件进入暂存区称为一个历史文件,直到下一次其发生变化。详情可见下图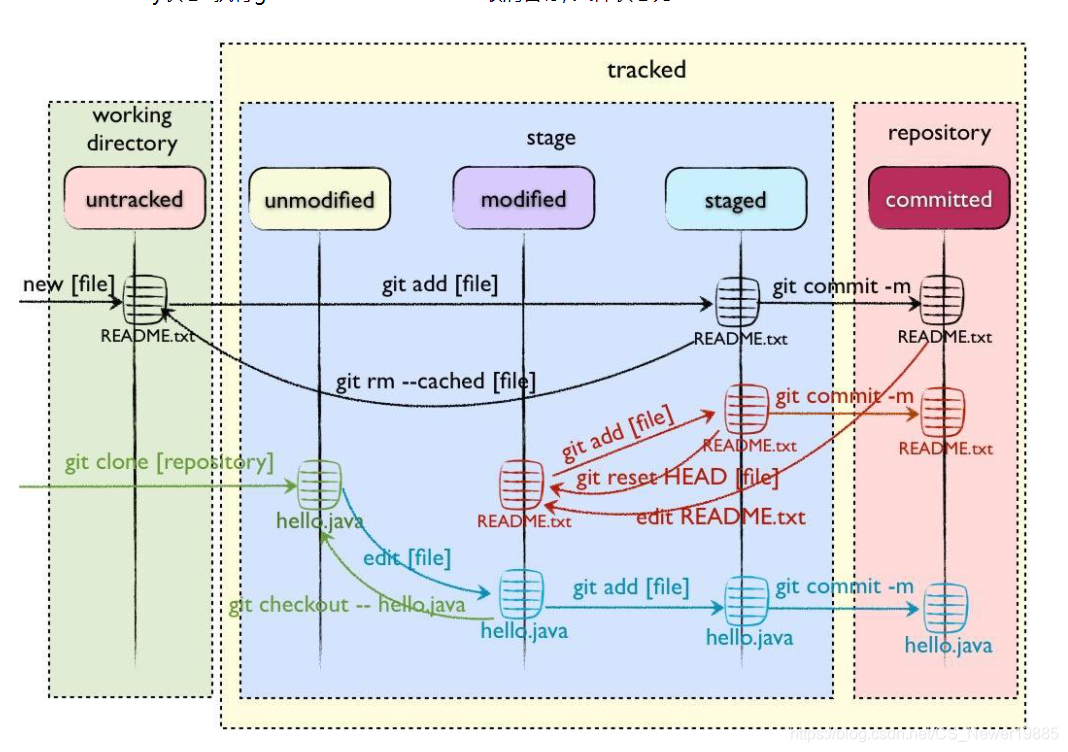
- HEAD
HEAD是一个常见的GIt概念,它其实就是一个指针,指向某一次提交,一般而言它会随着一条提交链而移动指向最新的一次提交。 - 常见符号及命令行操作
Git中有几个常见的符号:.指所有可操作的文件,一般我们在将某一个版本的文件提交称为一个新的版本的时候会用这个可以省去一个个敲入需要更新的文件。^一般和HEAD配合使用,HEAD^指HEAD的前一个版本,HEAD^^指HEAD前两个版本,而如果需要更多的版本则可以用HEAD~n来指向。
- Git与Github
Github是一个大型代码托管平台,其实是许多远程仓库的所在网站,我们也可以把自己的远程仓库建立在上面,更详细的情况可以看下文远程仓库的部分。3 Git安装
3.1 Linux系统
如果是在Linux系统下可以直接通过命令行进行安装,例如Debain系下的可以通过sudo apt-get install git-all来实现安装。3.2 Windows系统
Windows系统下可以在Git的官网下安装,下载完成之后一路next即可完成安装。4 Git基本操作
下面介绍Git的基本操作,首先介绍本地Git仓库的操作,再介绍与远程仓库的连接与交互。4.1 基础操作
初始化仓库
git init
这个命令没有太多可说的,直接使用即可,之后在文件夹中会生成一个.git的隐藏文件夹,这个文件夹就是用于保存这个Git工作目录的相关信息的,随着开发的进行这个文件夹的大小会逐渐膨胀。将文件保存到缓存区
在初始化完成之后,如果当前文件夹中原来有部分文件,则需要手动将已有文件添加到缓存区当中(同时也是将这些文件标记为追踪状态),可以通过下面的命令:git add [filename|dir|.]
来实现,其中如果使用.作为最后的参数则会把当前文件夹中的所有文件添加进去。而如果有多个文件或文件夹则文件与文件之间直接使用空格隔开即可。如果想把文件从缓存区中删除则可以使用下面的两条命令:
git rm --cached [filename] or git rm -r --cached [dir|.]
git reset <HEAD|log> [filename]这条命令的意思是用版本库中的对应文件来替换当前的缓存区,从而实现相同的效果。查看文件状态
如果想要查看当前文件夹中的文件状态,可以通过git status [|filename]
实现。如果参数为空则会列出当前目录下所有的文件状态。查看同一文件不同版本之间的不同
通过以下命令可以查看同一文件不同版本之间的不同:1
2
3
4git diff [filename] 查看当前工作区文件和暂存区的不同
git diff HEAD [filename] 查看工作区和之前已提交的不同
git diff [HEAD|log] [HEAD|log] [filename] 查看两个不同版本之间的不同
git diff --cached [HEAD|log] [filename] 查看暂存区和已提交文件的不同敲入命令后会出现以下这样的界面:
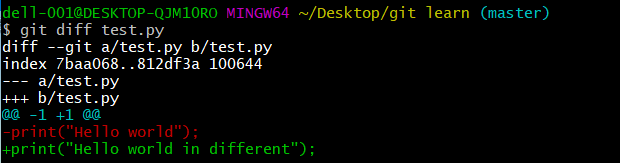
红色和绿色表示的就是两个文件之间的差异,其中— a表示的是修改前的文件,而+++ b表示修改之后的文件。下面的红绿字体同样对应,红色字前有一个-表示这是修改前的内容,绿色字体前+表示这是修改后的内容。签出命令
签出命令对应的是git checkout,这个命令有多个用途。- 切换分支
通过git checkout [branch]可以在不同的分支之间切换,详情见下文分支操作部分。 - 取出文件进行覆盖
签出命令可以将文件从缓存区取出到工作区,也可以从版本库中取出来覆盖缓存区和和工作区,命令如下:1
2git checkout --filename 用缓存区filename文件覆盖工作区filename
git checkout branch --filename 用branch中的filename文件覆盖工作区和缓存区的filename
- 切换分支
建立一个提交
终于在完成一个功能的开发之后可以进行版本迭代了,这个时候我们需要进行一次提交来将新写的代码从缓存区转移到版本库,这个过程就称为提交。提交的命令如下:1
2
3
4git commit -m [message] 普通提交,可以直接commit,之后在vim中填写message
git commit [file1] [file2] 指定部分文件进行提交
git commit -a 相当于git add . + git commit
git commit -v 提交时显示所有diff信息其中如果不加
-m选项,则会跳出这么一个界面:
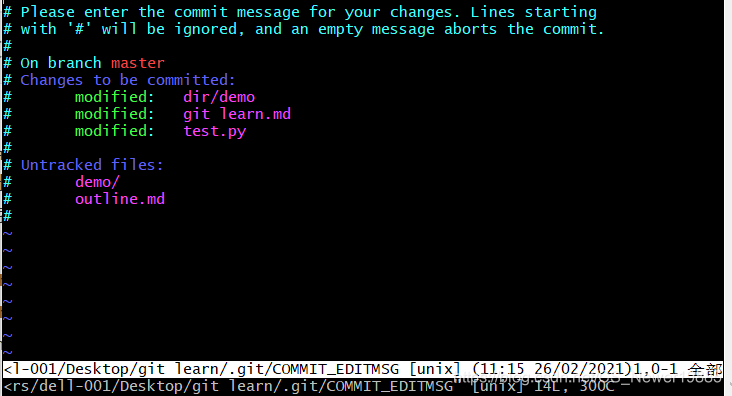
对于新手来说可能不知道这个界面是怎么回事,同时还发现无法操作。这个界面要求我们输入提交的信息(commit message),也就是带有-m选项中的后面的[message]。而当前处于的是一个叫做Vim的编辑器,这里只介绍最基础的操作,按下i即可开始编辑,编辑完成之后按下ESC结束编辑,再依次按下:wq回车结束即可。当然能够提交也要能够撤销提交,如果在一次提交之后发现有错误,那这时我们可以通过两种方式进行补救:
- 覆盖法
将需要修改的文件修改完成之后,重新添加到暂存区,之后通过
git commit --amend即可用一次新的提交来覆盖上一次提交,其中暂存区中同名的文件会被替换,而其他文件则保留在这个版本当中。 - 撤回法
如果错误一时半会儿解决不了,则可以通过下面的命令撤回提交
git reset --hard HEAD~1
其中1也可以替换为任意数值,表示当前HEAD指向前的n个版本。
- 覆盖法
总结
以上的操作可以通过一张图简单的概括一下:
当然Git当中有许多相似的操作,他们可以针对不同的情况来使用,这里就不做过多介绍,感兴趣的话可以自行上网搜索。
4.2 分支操作
在掌握了上面的基本操作之后,我们基本上就能够用Git来进行版本的控制管理了,但是在实际开发中,我们还会遇到多分支开发的情况,这时候就需要学习分支操作了。
创建一个分支
在创建Git仓库之后会默认生成一个master或main分支,而如果想要创建一个新的分支,可以通过
git branch [branchname]
实现。切换分支
在创建出新的分支之后,想要切换到这个分支去,可以用上面提到的checkout命令:
git checkout [branchname]而创建切换两步其实可以通过一步来完成
git checkout -b [branchname]这样如果原来不存在branchname分支则会自动创建并切换过去。注意:切换分支之后缓存区和工作区都会被新分支的最新提交所覆盖,所以在切换之前需要先把缓存区与工作区中刚刚完成的内容提交到分支当中,然后再进行切换,防止内容丢失。
分支合并
当你和你的小伙伴分别都完成了各自的开发内容后,现在需要将你们两个负责的分支合并起来变成完整的版本,这个时候就需要分支合并了。分支合并可以通过以下命令实现:git merge [branchname]
这条命令会把branchname分支合并到当前所在分支当中,所以在合并之前要记得先切换分支哦。
当然了,分支的合并没有那么简单,加入你和你的小伙伴在开发过程中都对某一个文件做出了修改,合并的时候就会提示分支之间存在冲突(conflicts),冲突显示的方式与上文`diff`的样式相同,这个时候就需要你们进入文件,对冲突的部分进行协商然后进行修改了。 通常冲突会保留在文件当中,如下图所示
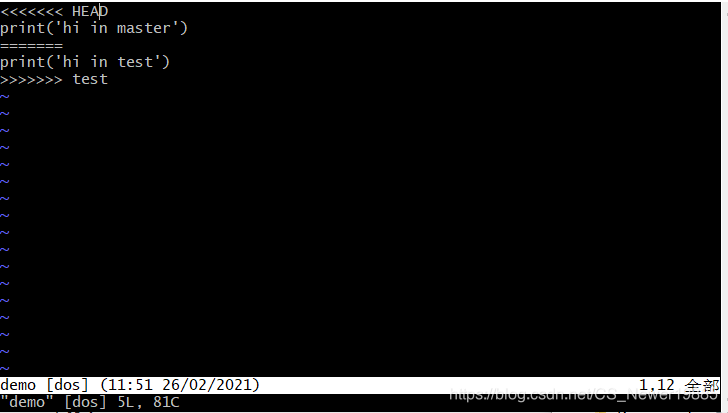
图中使用`<<<<<<<< branchname``=========``>>>>>>>>>>> branchname`分隔开两个不同的分支中同一个区域的不同内容,我们在修改的时候可以选择保留其中一个,也可以两个都保留,最后记得删去分隔线,在冲突解决好之后,这时**不使用`merge`命令**,而是需要将这个修改后的文件添加到缓冲区,之后提交即可:
1
2
git add [冲突文件]
git commit -m [message]
在冲突解决之后右侧的状态会发生变化

可以看到MERGING消失。
当然除了`merge`命令之外,Git还提供了一个`rebase`命令也可以用于分支合并,`rebase`命令会将另一个分支的所有提交全部复制到新的分支上,从而在新的分支上产生许多新的提交,具体入下图所示:
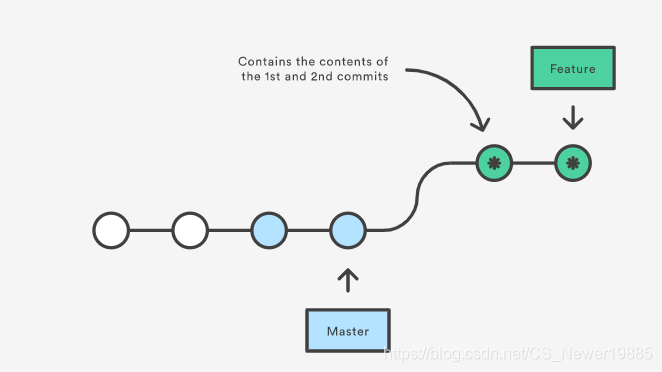
关于二者的区别,[点击查看详情](https://www.atlassian.com/git/tutorials/merging-vs-rebasing)
- 删除分支
在分支合并完成之后,原有的分支就不再需要了,这时可以通过:git branch -d [branchname]删除。4.3 应用操作
在介绍完基本的操作之后,我们聚焦于应用类的操作,主要设计日常开发过程中的一些常见操作。4.3.1 多分支开发
在日常的开发过程当中,我们通常不会直接在master分支上直接进行迭代更新,而是会另外设置一些分支,常见的分支如下:
- master分支:主分支,仅用于记录关键版本节点;
- develop分支:开发分支,从master分支中分出,用于记录每个小的版本更新。
- feature分支:从develop分支分出,用于开发某个小功能,开发完成后合并回develop分支。
- hotfix分支:用于紧急修复,从master分支分出,修复完成后合并回master分支,然后再从把master分支合并到develop分支从而将修复内容也转移到develop分支。
- release分支:用于版本发布,从develop分支分出,通常需要在这个分支上进行代码注释,相关文件的版本号修改,完成之后合并到master分支,再在master分支上打上tag,一次版本更新就完成了。
总结起来就是下图这样:
4.3.2 代码回滚
代码回滚总共有3中类似但不同的命令,下面一一进行介绍:
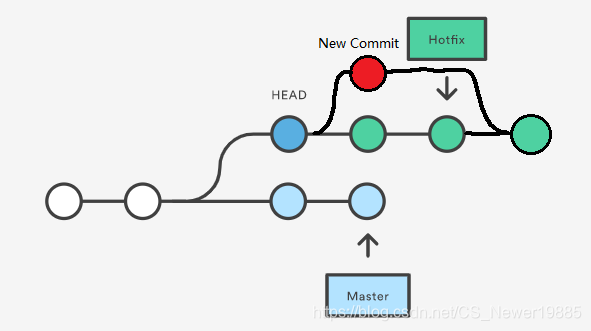
checkout:这个命令我们之前有提及过,这里进一步解释以下,这个命令主要是用于查看之前的某个提交,会将HEAD转移到之前的某个提交上,保持原来的版本库不变,具体可见下图:


我们输入git checkout HEAD^^,看到此时HEAD指针指向了前两个版本节点,但是整个版本库的树形结构没有发生改变。值得一提的是,这种方式虽然没有对树形结构进行破坏,但也正是如此,如果想要在这种情况下做出修改,我们不能简单地直接修改后提交,而是要另外再在这个节点上分出一个分支,修改提交之后再将这个分支合并回去,如下图所示。所以
checkout命令才更主要用于查看而非修改。
reset:与
checkout相对,reset命令则会破坏原来的树状结构,会将该分支返回后的节点以后的所有节点删除掉,如下图所示。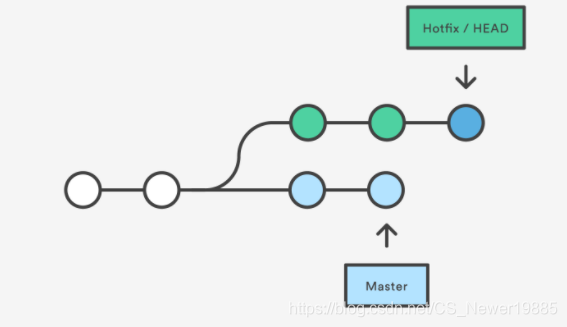

reset命令的作用就是更加纯粹的用于撤销之前的修改重新对之前的代码进行改动,可以看到相比checkout,reset在修改之后重新生成一个新的提交会方便很多。但是这样做的危害则是抛弃之前所做的一些修改,同时如果这个分支已经共享给了其他人,这么做很有可能会造成大量的冲突,甚至也有可能抹除他人所做的一些修改。revert:revert命令算是随着Git的更新后来跟上的一个命令,这个命令主要是为了解决
reset命令中存在的痛点,即无法在多人协作的项目中使用。revert相比reset的不同点在于它并不会“返回”之前的那个节点,而是把之前的一个节点挪到当前节点的下一个节点位置,然后再由你进行修改,详情可见下图: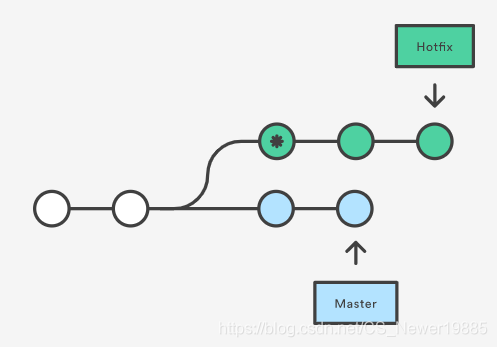

这么做在多人协作的项目中会有更好的效果,但是如果分支不需要和别人共享,那么这么做则会使Git历史记录变得冗余繁杂,同时也增大的存储占用。4.4 远程仓库
当我们需要一个团队一起合作完成任务的时候,我们就需要有一个共同的远程仓库来存放整个团队的代码了,下面我们就来介绍远程仓库的相关操作。
远程仓库建立
通常我们会将远程仓库建立在代码托管平台,例如GitHub,Gitee等平台,这里以GitHub为例简单展示如何建立。左上角找到如下界面,点击New开始建立一个仓库
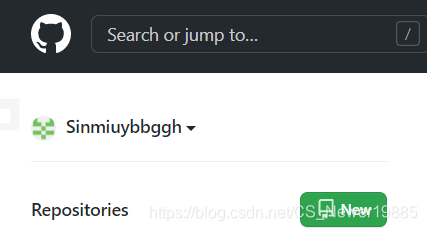
然后填写上仓库名称,描述等内容,然后可以选择是公有(public)还是私有(private),注意个人仓库私有是免费的,但是团队仓库私有需要收费,如果不想付费的话可以考虑Gitee等其他平台。最后点击最下方create即可。
之后会进入这样一个界面,将仓库的SSH地址复制下来,在命令行通过git clone URL按下Insert键即可粘贴。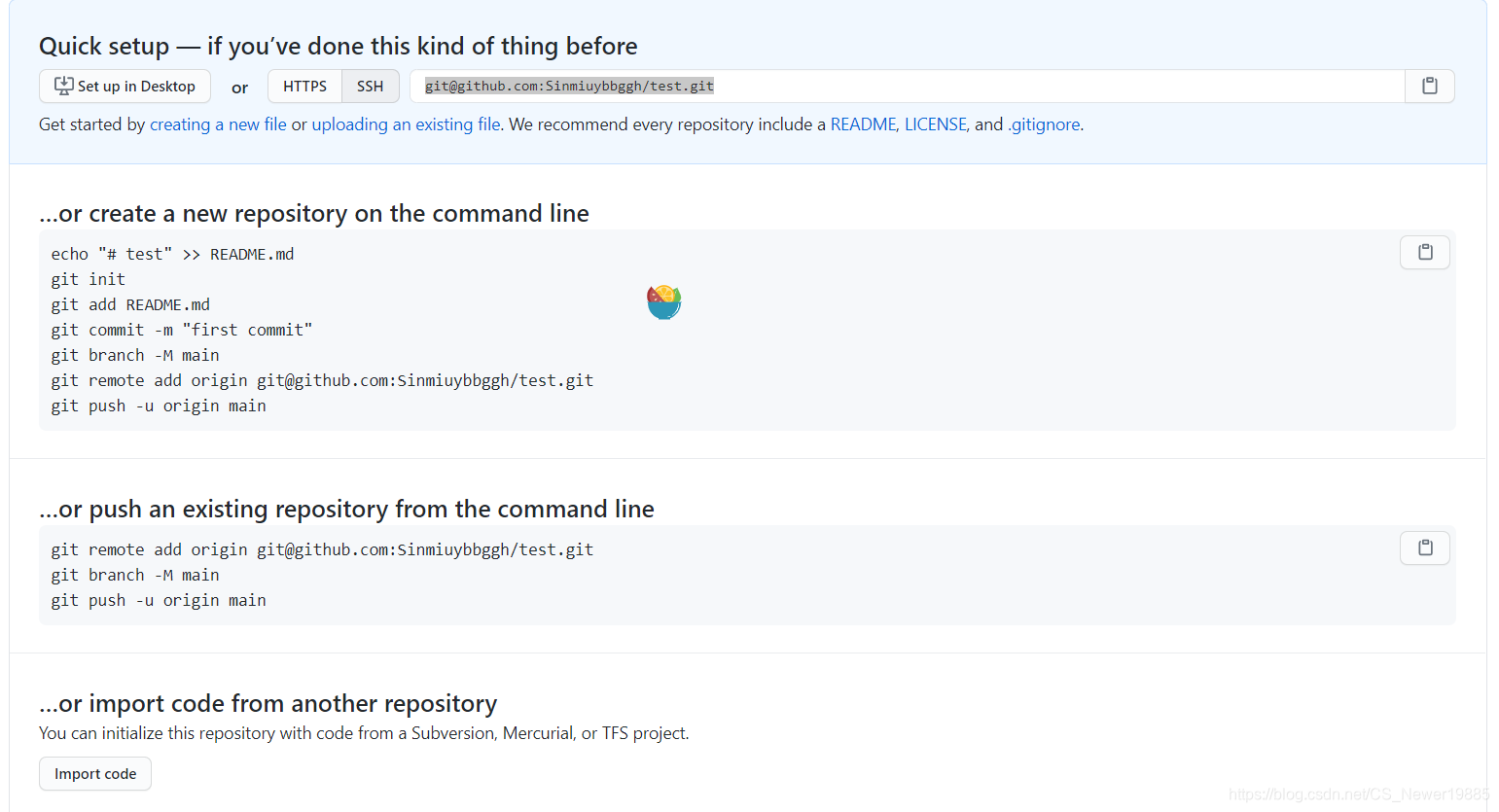
但是也有可能出现下面这样的情况。这是因为GitHub网站还不认识你这台电脑,需要使用一个SSH密钥来指定你这台电脑,在你的GitHub网站中设置一下即可,点击查看详情。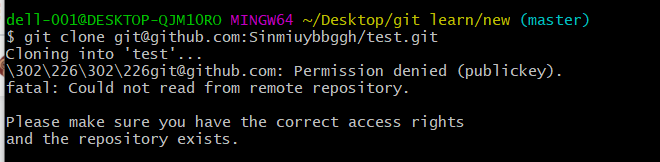
当然如果你的电脑上安装了GitHub Desktop,则可以直接点击Set up in Desktop一键完成。克隆
上面其实我们已经介绍了如何把自己建立的GitHub仓库克隆到自己的电脑上,其实就是通过git clone URL
来实现的,这里再介绍一下如何克隆别人的仓库。
进入别人的仓库后会是这样的一个界面,点击绿色的按钮Code会出现如下界面。
点击右边的按钮复制即可,其他同上。抓取
当我们想要和远程仓库取得同步的时候,我们就需要使用抓取(fetch)和拉取(pull)两个命令。抓取的作用是从远程仓库获取它的所有版本库中的内容并用于更新本机的版本库,但是保留当前缓存区和工作区的内容,具体命令如下。其中name是远程仓库的名字,通常是origin,当然也可以自己进行设置。1
2git fetch [name] [branch] 只抓取特定分支
git fetch [name] 抓取所有分支抓取到的分支会被命名为
name/branch,之后如果要将当前的分支与远程分支进行合并,则可以通过merge或rebase命令实现。拉取
拉取相当于将抓取与合并两步合起来,具体命令如下:
git pull <远程主机名> <远程分支名>:<本地分支名>
如果省略冒号后面的内容,则会与当前分支进行合并,同时在克隆的时候会自动建立和远程分支的跟踪关系,从而可以只保留远程主机名。当然跟踪关系也可以手动建立,通过
git branch --set-upstream [local_branch] [远程主机名/分支名]实现。同时如果我们希望直接用远程分支来覆盖本地对应的追踪分支,可以通过如下命令:
git pull --rebase <远程主机名> <远程分支名>:<本地分支名>注意:可能有人会有这样的疑惑,如果我在拉取的时候远程分支已经被删除了,一经同步岂不是也会把我的分支给删除吗?这里大家可以放心,一般情况下是不会被删除的,如果想删除,需要在命令中添加
-p选项。推送
在完成了自己的任务之后,需要将自己的进度推送到远程主机上,这个时候就需要进行推送(push)了。命令如下:
git push <远程主机名> <本地分支名>:<远程分支名>
注意分支顺序和pull相反。同上如果省略远程分支名则会自动推送到存在追踪关系的分支,如果没有则会新建一个该名字的分支。如果省略本地分支名,则相当于删除某个远程分支。而如果只保留远程主机名,则自动将当前分支推送到与之有追踪关系的分支。
5 Git团队开发规范Gitflow
Git这项工具在开发的时候并没有设定什么规范,但是我们在开发的过程中如果不遵守一定的规范则很容易导致错误,甚至会破坏整个团队的成果,所有就有人逐渐总结Git的使用方法,发明出了工作流的说法,这里我们就简单介绍一下Gitflow这一工作流的基本原则。
master分支master分支应该是稳定的,可以轻松地被获取到然后编译使用,同时也是hotfix(热修复)分支的出发点。develop分支
develop分支是开发分支,代表开发的最前沿(bleeding edge),在这个分支中分出feature分支用以开发新的功能。不允许直接在
develop和master分支上进行开发分支名应该具有概括性,例如修补分支fix-xxxbug,release-X.X.X
在开发完一个
feature分支之后,想要并入develop分支,首先要通过pull获取最新的develop分支并消除conflicts如果还没有将当前的这个
feature分支传到远程主机(feature完全在本地),则首先将远程端的develop分支rebase到本地(相当于更新本地的develop分支),然后将feature分支merge到develop分支并解决冲突(这个步骤在本地完成),最后将develop分支push到远程主机,然后本地的feature分支就可以删除了。而如果已经将这个
feature分支传到远程主机(feature同时在本地和远程主机),则首先将develop分支merge到feature分支,然后再将feature分支merge到develop分支,最后推送到远程主机,并删除feature分支。code review
Code review是指同事之间互相阅读代码并给出自己的意见或想法的过程。通过
pull request来进行code review,同时让打开pull request的人来将分支合并到远程主机中,在原作者为同意意见之后由写code review的人将代码合并到主分支。pull request会在其他人想要将自己的分支合并到远程主机的分支时提出,字面意思是提出者希望原作者能够将他们的分支pull到项目代码当中
在develop分支开发完成准备要发布的时候,首先需要将develop合并到master分支当中,注意此时合并的时候要带上
--no-ff选项,从而避免合并出fast-forward类型。而新的提交可以打上X.X.X的tag,然后再将master合并到develop分支中,这样develop分支中也会有版本号的tag。
什么是fast-forward:
如下图
当在master分支进行bugfix之后,现在要合并回去,如果原master分支没有更新,那么直接merge的话会变成下面这样:

如果加上--no-ff选项

区别在于此时master分支直接移动到了bugfix这里,而没有形成一个新的提交,这里git是偷了一个懒。但是问题会出现在如果将这个bugfix分支删除掉的时候,如下两图所示:
这是直接merge
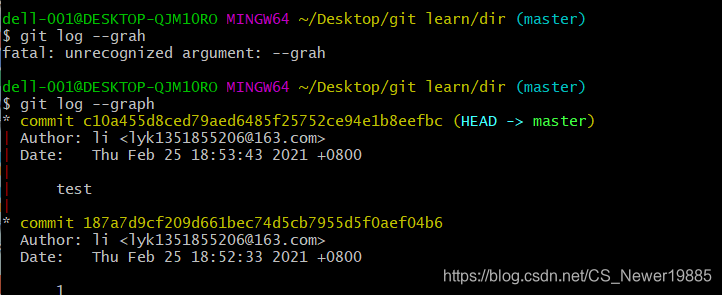
这是使用--no-ff选项。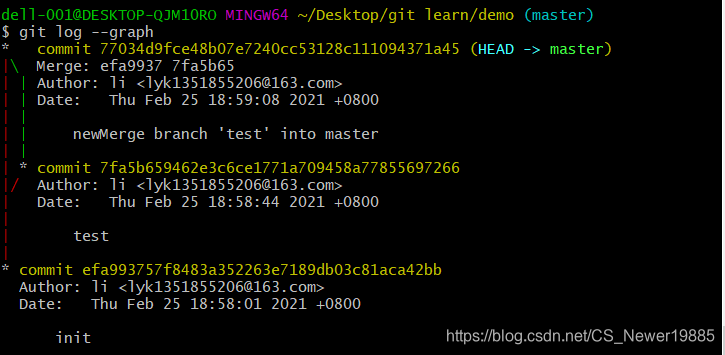
可以看到,非fast-forward的情况下会生成多一个提交在主分支上,这里就可以写上bug-fix,也能看到整个bug-fix的过程的提交信息,而如果不加,在删除掉之后就只剩下最后一次的bug-fix的提交信息,不利于后续的回滚。
bug-fix
在发现bug需要修改的时候,要从master分支中分出分支然后修改,修改完成后合并回去(注意–no-ff),然后将master分支合并到develop分支。
Commit message
在写commit message的时候,使用一般现在时,不使用三单形式,第一行书写Summary,一般在50词以内,如果需要进一步说明则换行使用段落的格式进行,注意正确的标点和大小写,并且控制在72列以内就要换行。
release
release分支从develop分支中分出,首先生成一个新的分支release-X.X,(然后通过一个固定脚本将代码中的版本号统一进行修改),然后git commit -a即可,之后切换回master分支,在这里用–no-ff合并刚刚的release分支到master分支,然后通过git tag -a X.X打上tag,最后将release分支删除即可。
6 总结
Git的使用是团队开发过程中难以避免的一环,正确的使用Git可以为开发节省下大量的精力,但同时错误地使用也可能造成整个团队项目的崩溃,所以对Git的学习使用一定要规范正确,多加练习,才能在真正需要的时候发挥出它的强大威力。
7 参考资料
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick Start
Create a new post
1 | $ hexo new "My New Post" |
More info: Writing
Run server
1 | $ hexo server |
More info: Server
Generate static files
1 | $ hexo generate |
More info: Generating
Deploy to remote sites
1 | $ hexo deploy |
More info: Deployment